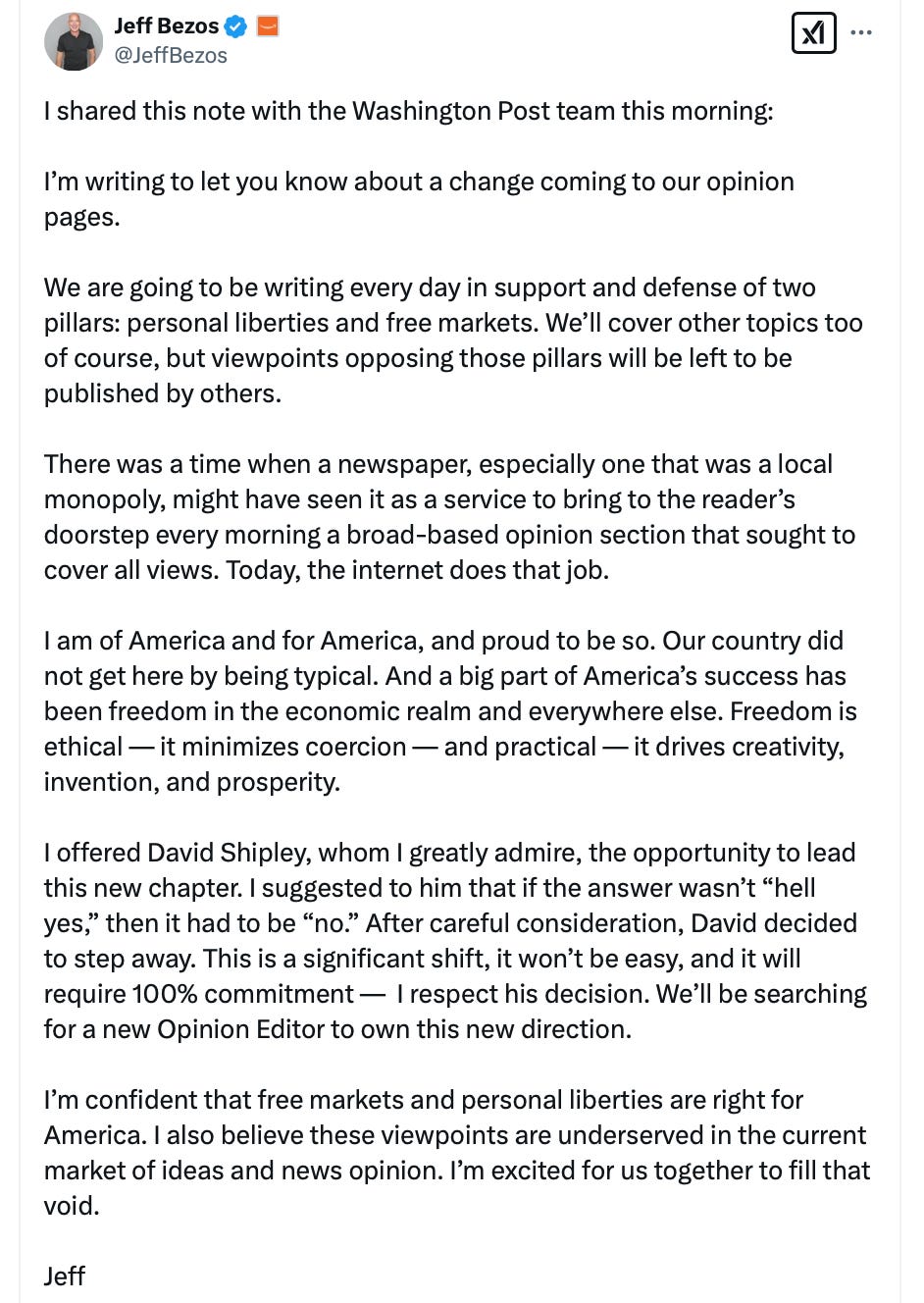
The Ink; Jeff Bezos, owner of The Washington Post, just sent out this email of total submission.
[Kip Currier: Nail by nail by nail by nail, the three richest persons on the planet -- Elon Musk (Twitter/X), Jeff Bezos (Amazon/Washington Post), Mark Zuckerberg (Meta/Facebook/Instagram/WhatsApp/Threads) -- are erecting barriers to information and solidifying control of their versions of information.
Note what Bezos, in part, wrote today:
"We are going to be writing every day in support and defense of two pillars: personal liberties and free markets. We'll cover other topics too, of course, but viewpoints opposing those pillars will be left to be published by others."
Point 1: Bezos's prior conduct tells us that he will decide how the two pillars of "personal liberties" and "free markets" are defined. That's censorship of ideas and free expression.
Point 2: Bezos will determine the parameters of "viewpoints opposing those pillars". That's also censorship of free speech.
Point 3: Bezos downplays the time-honored tradition of U.S. newspapers providing "a broad-based opinion section that sought to cover all views" by stating that "Today, the internet does that job." This is an abject abandonment of the historical role of one of the nation's foremost papers of record; indeed, the very newspaper that exposed the Watergate scandal that brought down the presidency of Richard Nixon. Bezos knows, too, that the internet is rife with misinformation and disinformation. A chief reason that readers seek out creditable, trusted news providers like The Washington Post is the expectation of fact-checking and responsible curation of opinions and facts. Bezos's statement amounts to disingenuous dissembling and the ceding of responsibility to the Internet and social media, which he well knows are highly flawed information ecosystems.
Point 4: Bezos states later that "freedom is ethical". But freedom always comes with ethics-grounded responsibilities. Nowhere in Bezos's statement does he talk about ethical responsibilities to truthfulness, free speech, accountability, transparency, the public/common good, constitutional checks and balances, or the rule of law, all of which are integral to informed citizenries and functioning democracies.
Bezos's actions and viewpoints are antithetical to free and independent presses like The Washington Post, as well as to the core principles of one of the world's oldest democracies.]
[Excerpt]
"Jeff Bezos, owner of The Washington Post, just sent out this email of total submission.
Bezos appears to have misread Timothy Snyder’s advice “Do not obey in advance” as “Obey in advance,” missing a couple words."