Margaret Sullivan, The Guardian ; Jeff Bezos is muzzling the Washington Post’s opinion section. That’s a death knell
"Owners and publishers of news organizations often exert their will on opinion sections. It would be naive to think otherwise.
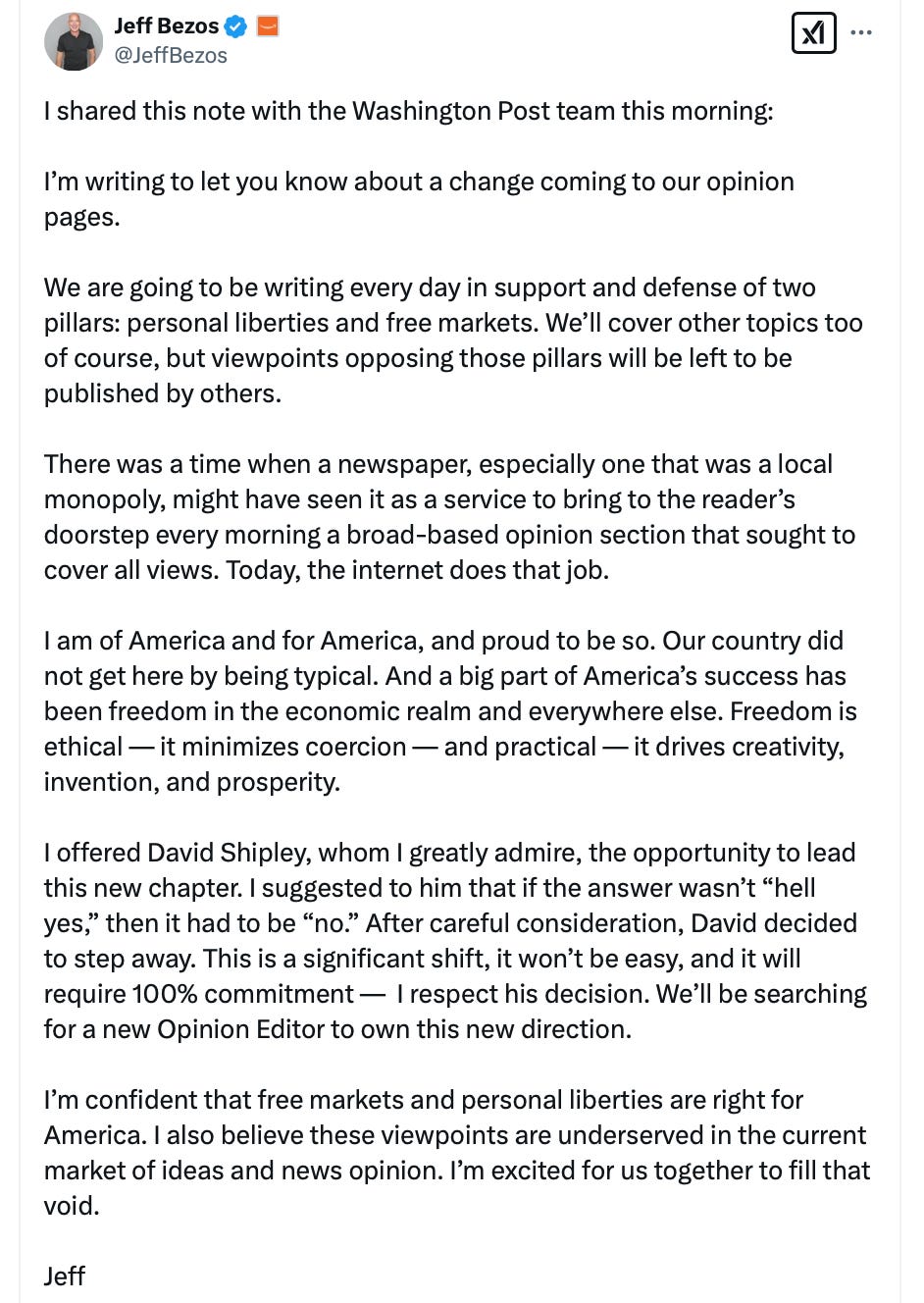
But a draconian announcement this week by Jeff Bezos, the Washington Postowner, goes far beyond the norm.
The billionaire declared that only opinions that support “personal liberties” and “free markets” will be welcome in the opinion pages of the Post.
“Viewpoints opposing those pillars will be left to be published by others,” he added.
The paper’s top opinion editor, David Shipley, couldn’t get on board with those restrictions. He immediately – and appropriately – resigned.
Especially in the light of the billionaire’s other blatant efforts to cozy up to Donald Trump, Bezos’s move is more than a gut punch; it’s more like a death knell for the once-great news organization he bought in 2013...
What is clear is that Bezos no longer wants to own an independent news organization. He wants a megaphone and a political tool that will benefit his own commercial interests.
It’s appalling. And, if you care about the role of the press in America’s democracy, it’s tragic.
“What Bezos is doing today runs counter to what he said, and actually practiced, during my tenure at the Post,” Martin Baron, the paper’s executive editor until 2021 and the author of the 2023 memoir Collision of Power: Trump, Bezos and the Washington Post, told me in an email Wednesday.
“I have always been grateful for how he stood up for the Post and an independent press against Trump’s constant threats to his business interest,” Baron said. “Now, I couldn’t be more sad and disgusted.”...
This outrageous move will enrage them. I foresee a mass subscriber defection from an outlet already deep in red ink; that must be something businessman Bezos is willing to live with.
He must also be willing to live with hypocrisy.
“Bezos argues for personal liberties. But his news organization now will forbid views other than his own in its opinion section,” Baron pointed out, recalling that it was only weeks ago when the Post described itself in an internal mission statement as intended for “all of America”.
“Now,” Baron noted, “its opinion pages will be open to only some of America, those who think exactly as he does.”
It’s all about getting on board with Trump, to whose inauguration Bezos – through Amazon, the company he co-founded – contributed a million dollars. That allowed him a prime seat, along with others of his oligarchical ilk."